Build nodes you can replace — and trust.
Don’t accept random kernels as peers.
kubedOS is a self-healing JeOS for Kubernetes clusters on Proxmox. It’s designed for cloning and redeploying, not hand-maintaining “pet” servers. The big difference: node trust starts at boot (Secure Boot + TPM), and new nodes can be quarantined until they prove they’re running what you signed.
If you plan to “feed the Kuber-beast” (lots of nodes, lots of rebuilds), the easiest compromise is a poisoned image. kubedOS makes the safe pattern boring: taint first → verify boot identity → then schedule workloads.
What kubedOS is
kubedOS is a Proxmox-native cluster bring-up that treats a Kubernetes cluster as a single deployable object. Proxmox defines VM lifecycle and placement; kubedOS defines deterministic boot, networking, and enrollment.
A cloneable node baseline
Nodes are cattle. If a node breaks, you replace it — you don’t spend your weekend nursing it back. That only works if every replacement is built from the same baseline.
- UEFI-only. No legacy boot escape hatches.
- Secure Boot + TPM. Hardware-backed boot trust as minimum bar.
- Deterministic first boot. Backplanes come up before “cluster stuff”.
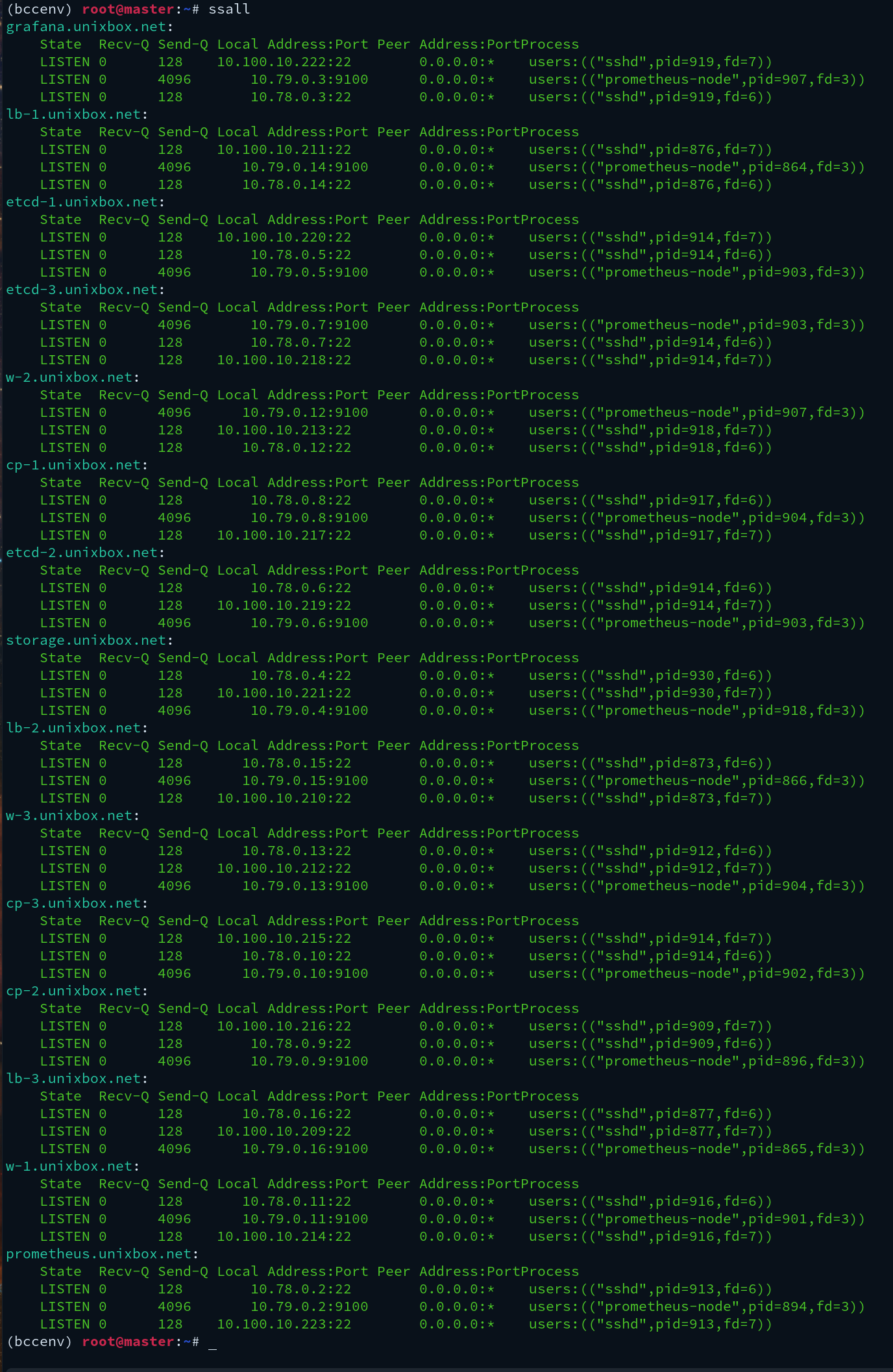
Explicit L3 backplanes (WireGuard)
Networking is not “magic overlay stuff”. It’s explicit kernel L3 interfaces you can reason about. Separate planes make both ops and security simpler.
- wg-mgmt for admin/control access
- wg-obs for telemetry
- wg-k8s for Kubernetes control/data
- wg-sec for cluster security services (optional)
Baseline security: Secure Boot + TPM (plain terms)
A lot of Linux people see “Secure Boot” and immediately disable it. In security work, that’s backwards. Secure Boot + TPM are the boring norm because they solve a simple problem: how do you know the machine booted what you think it booted?
Secure Boot
Only a signed boot chain is allowed to run. If someone swaps your bootloader/kernel, it fails early.
- Stops casual bootkits. The machine won’t silently boot compromised code.
- Makes tampering loud. “Won’t boot” beats “boots and lies”.
- Works in real life. You can still sign what you need.
TPM 2.0 (Measured Boot)
TPM measures parts of the boot process and can produce an attestation quote. That gives you something you can verify before granting trust.
- Records boot measurements (PCRs).
- Enables attestation. “Prove your boot state” becomes a real check.
- Works in Proxmox too. vTPM gives VMs a measured-boot identity.
Node intake: taint first → verify → unlock
Kubernetes will accept a node if it can register. That’s convenient — and dangerous at scale. kubedOS pushes the safer habit: new nodes join quarantined until you verify boot identity.
The workflow (no jargon)
- New node joins untrusted. It exists, but it runs nothing important.
- It proves boot identity. Verify Secure Boot + TPM measurements.
- Then you unlock it. Remove taint / apply “trusted” label.
Why this matters (especially for “lots of nodes”)
- Poisoned images scale instantly. One bad artifact becomes many bad nodes.
- SSH proves access, not integrity. A compromised node can still log in “normally”.
- Boot trust is the missing primitive. Verify the kernel/boot chain, not the claim.
Minimal enforcement: taint on join
Small change, big safety: new nodes do not run workloads until you explicitly clear them.
# Option A (preferred): register as untrusted
--register-with-taints=node.kubedos.com/untrusted=true:NoSchedule
# Option B: taint after join
kubectl taint nodes <node> node.kubedos.com/untrusted=true:NoSchedule
# After verification passes:
kubectl taint nodes <node> node.kubedos.com/untrusted=true:NoSchedule-Two-phase deployment (and why it’s a feature)
kubedOS splits deployment into two clean phases so you can keep the “ugly bootstrapping” separate from the cluster build. This is what makes it deterministic, auditable, and easy to rerun. You can also combine them into a single step when you want “just build the whole thing”.
Proxmox creates/clones VMs, firstboot runs, and kubedOS places the WireGuard keys/certs/materials in predictable locations. That means you can either:
- Inject into an existing WireGuard mesh (reuse your current fabric), or
- Let Phase 2 consume those materials and build the full cluster wiring automatically.
This phase takes the now-reachable nodes and applies the full build: networking policy, kube components, and configuration (e.g. via
apply.py + Ansible). Same inputs → same cluster.
For “I just want the cluster now”, Phase 1 and Phase 2 can be chained into a single command. The separation remains important because it keeps the system testable and recoverable.
Why splitting helps
- Debuggable. You can prove backplanes/identity before “cluster complexity”.
- Composable. Plug into your existing WG mesh without rewriting everything.
- Safer. Gate node trust before you hand it workloads.
What “deterministic” means here
- Proxmox is authoritative. VM lifecycle is declared and repeatable.
- Networking is explicit. No mystery overlays.
- Bring-up is idempotent. Re-apply should converge, not drift.
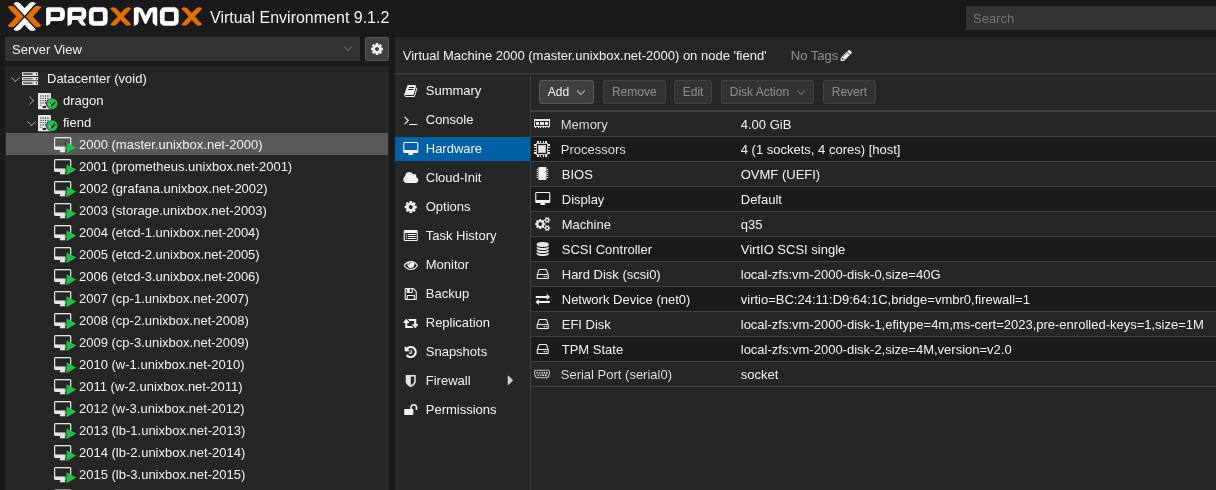
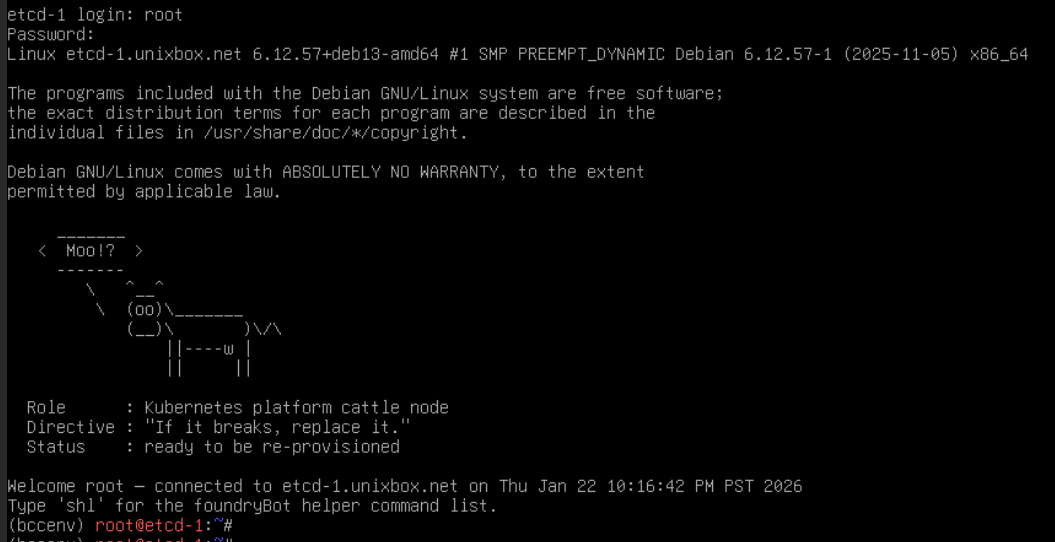
Examples (real lab output)
Raw screenshots from bring-up. These live in public_html/img/, so the paths below are img/<filename>.

Next docs we’ll publish (focused and practical)
- TPM verification gate: how the verifier checks boot measurements and auto-unlocks nodes.
- Quarantine behavior: what untrusted nodes can talk to (and what they can’t).
- One-step vs two-step: how to chain phases while keeping the system auditable.
Why this matters
Linux makes it easy to build a cluster. It doesn’t make it easy to prove you’re feeding the cluster known-good kernels. kubedOS makes boot trust the default so scaling doesn’t mean scaling compromise.
You get…
- Proxmox-native bring-up you can repeat.
- Explicit WireGuard backplanes as the foundation.
- Secure Boot + TPM baseline for hardware-backed verification.
- Safer node intake: taint first → verify → unlock.
You avoid…
- Snowflake nodes that drift and rot.
- Blind trust of anything that registers.
- Hidden networking that’s hard to audit.
- Push-only chaos during bootstrapping.